










Analyse de puissance centrée sur l’émulation de conceptions de SoC

Lauro Rizzatti, expert en vérification, a récemment interviewé Jean-Marie Brunet, directeur senior du marketing de la division Scalable Verification Solutions Division (SVSD) de Siemens EDA, sur l’importance d’une estimation et d’une optimisation précises de la puissance pour la conception de systèmes sur puce (SoC).
Quel problème l’industrie des semi-conducteurs rencontre-t-elle aujourd’hui face à l’estimation de puissance pré-silicium ?

Jean-Marie Brunet
Le problème réside dans l’écart entre la consommation d’énergie dynamique pré-silicium estimée dans les conceptions de SoC et la puissance réelle dissipée par le SoC fabriqué. Ces dernières années, les clients ont remarqué que lorsque de nouveaux SoC étaient branchés dans les sockets des produits finis, la consommation d’énergie dynamique réelle dépassait d’un ordre de grandeur la puissance estimée.
Il est devenu essentiel de prévoir avec précision la consommation d’énergie réelle lors de la conception et de la vérification des nouveaux modèles.
La principale cause de cette divergence est le passage de la technologie CMOS planaire traditionnelle à la technologie des semi-conducteurs FinFET. Historiquement, la technologie CMOS traditionnelle a souffert d’importantes fuites de courant en mode veille ou statique. En se déplaçant vers les nœuds inférieurs, en dessous de 32 nm, le courant de veille a augmenté de façon exponentielle et est devenu ingérable. La technologie FinFET a permis de réduire considérablement le courant statique. Malheureusement, il n’a pas modifié de manière significative le courant de commutation ou le courant dynamique.
Pouvez-vous nous en dire plus sur la dissipation de puissance dynamique dans les FinFET ?
Le transistor FinFET réduit considérablement les fuites d’énergie des dispositifs planaires grâce à une approche 3D. En relevant le canal et en enroulant les portes autour de celui-ci, la structure résultante permet un contrôle plus efficace des canaux, ce qui diminue les tensions de seuil et d’alimentation (Fig. 1).
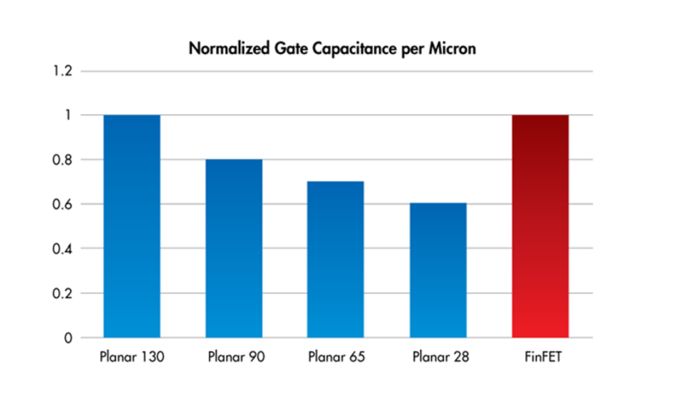
Figure 1 : Le schéma met en évidence la capacité des portes des FinFET par rapport aux processus planaires. (Source : Cavium Networks)
Dans les FinFET, la consommation d’énergie dynamique constitue la majeure partie de la dissipation totale de puissance en raison des capacités supérieures des broches par rapport aux transistors planaires. Il en résulte des chiffres de puissance dynamique plus élevés.
La conception à l’aide de la technologie FinFET exige des règles plus strictes qui tiennent compte des critères du processus FinFET. Comme les nouvelles règles limitent la synthèse, le placement, le pré-placement (floorplanning) et l’optimisation, les métriques de conception s’en trouvent affectées.
L’analyse de puissance au niveau RTL est désormais obligatoire. Elle doit commencer tôt dans le flux de conception et être effectuée à toutes les étapes du flux, en même temps que d’autres métriques de conception, telles que les performances et la surface. Le recoupement entre RTL, le code logiciel embarqué et le layout est essentiel pour identifier et déboguer les problèmes dès le début du processus de conception.
Quels autres problèmes contribuent à l’écart entre les estimations de la consommation d’énergie dynamique pré-silicium ?
Un autre problème important vient des limites intrinsèques du stimulus exerçant le circuit sous test (Design Under Test) lors de la vérification pré-silicium.
Aujourd’hui, l’industrie électronique a massivement recours aux bancs d’essai (benchmlarks) pour évaluer les performances et la consommation d’énergie des nouvelles conceptions. Différents segments de l’industrie utilisent différents types de bancs d’essai.
Dans l’industrie mobile, un banc d’essai très populaire appelé AnTuTu évalue les performances et la consommation des smartphones et des tablettes. Pour la conception centrée sur les processeurs graphiques (GPU), les plus populaires sont Car Chase, Manhattan et tous les bancs d’essai Kishonti.
Dans le secteur de l’intelligence artificielle et du machine learning (IA/ML), la suite de bancs d’essai MLPerf mesure les performances et la consommation des frameworks logiciels de ML, des accélérateurs matériels ML et des plateformes Cloud de ML. Elle sert aussi bien à l’apprentissage qu’à l’inférence. En ce qui concerne le stockage, la mesure des IOP permet d’évaluer avec précision les performances et la précision des nouveaux dispositifs.
Il est impératif d’exécuter ces bancs d’essai dans le cadre d’une validation pré-silicium. La visibilité totale sur le circuit permet d’identifier les zones de consommation d’énergie excessive bien avant la fabrication du silicium et d’apporter des corrections.
Comment mesurer la consommation d’énergie dans la validation pré-silicium ?
Traditionnellement, la consommation d’énergie était mesurée au niveau des portes en suivant l’activité de commutation du DUT exercée par des bancs d’essai constitués de tests de régression. Cette approche pose deux problèmes.
Tout d’abord, les essais ont lieu très tard dans le cycle de conception. Bien que l’écart avec le silicium ne soit que de 5 %, cette méthode n’apporte pas assez de flexibilité pour corriger le problème dans la conception. Un meilleur compromis consiste à évaluer la consommation d’énergie dynamique au niveau RTL, ce qui conduit à un plus grand écart par rapport au silicium de l’ordre de 15 %, mais offre une plus grande flexibilité pour les changements de conception.
Deuxièmement, les vecteurs des bancs de test ne représentent pas bien la façon dont le circuit va être utilisée. Pour obtenir une estimation précise de sa consommation de puissance, il est important de capturer l’activité de commutation aussi précisément que possible dans le contexte du système cible qui exécute des charges de travail réelles et des bancs de test de performances/consommation, comme décrit précédemment.
Quelle configuration permet d’effectuer une analyse de puissance et comment y parvenir ?
Il est évident que la simulation RTL ne peut plus assumer cette tâche exigeante. Ce qu’il faut, c’est une approche hiérarchique, en commençant au niveau de l’abstraction de la conception et en progressant par étapes jusqu’au niveau RTL et au niveau des portes. Aucun outil ne peut plus faire tout le travail à lui seul. Au contraire, plusieurs outils présentant des compromis optimaux de caractéristiques peuvent accélérer l’estimation et l’optimisation de la puissance (voir le tableau 1 ci-dessous).
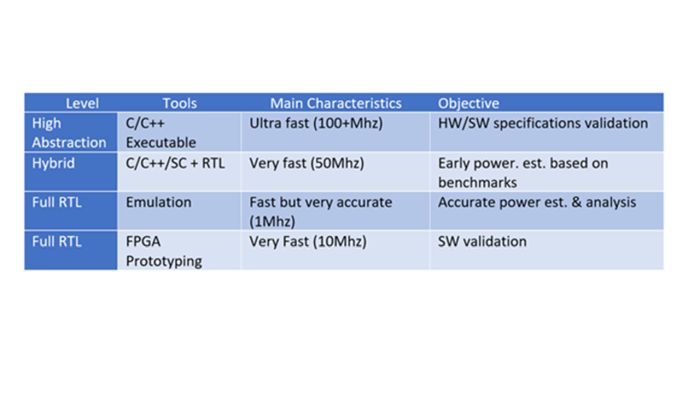
Tableau 1 : Une approche hiérarchique de l’estimation et de l’analyse de puissance est nécessaire pour accélérer le processus. (Source : Lauro Rizzatti)
Dans un premier temps, l’ensemble du DUT décrit en C/C++ à un niveau d’abstraction élevé est rapidement validé par rapport aux spécifications matérielles/logicielles, et une consommation d’énergie très approximative est estimée.
Ensuite, la dissipation de puissance est validée dans une configuration hybride consistant en une partie de la conception décrite à un haut niveau d’abstraction, généralement composé de cœurs de traitement et de mémoires comme les modèles Arm Fast, et de l’autre partie de la conception au niveau RTL. La section d’abstraction de haut niveau est exécutée sur un serveur hôte, le RTL est exécuté sur un émulateur matériel et les deux sont connectés via une interface basée sur des transactions.
Bien que l’émulateur fonctionne à une vitesse de quelques mégahertz, la configuration hybride peut atteindre des vitesses de l’ordre de 50 MHz, ce qui est suffisant pour démarrer rapidement Android, Linux et tout le noyau sous-jacent, ainsi que pour exécuter des bancs de test et des applications réelles.
Cette configuration offre un bon point de départ pour profiler la consommation d’énergie de l’ensemble de la conception dans un délai relativement court. En traçant l’activité de commutation sur une longue période de plusieurs milliards de cycles d’horloge, l’équipe de conception peut identifier les zones sensibles de dissipation de puissance élevée et faible dans une plage de quelques millions de cycles d’horloge. De même, en superposant les zones de dissipation de puissance sur un diagramme d’activité, l’équipe peut identifier visuellement les zones de conception à forte et à faible dissipation de puissance.
Une fois les zones sensibles et critiques identifiées, l’équipe peut passer au RTL complet et bénéficier d’une visibilité précise et détaillée sur chaque signal du circuit. En corrélant le diagramme d’activité au code logiciel embarqué et le diagramme d’activité au code RTL, l’équipe peut rapidement zoomer sur les zones présentant des problèmes de puissance potentiels.
Il est extrêmement important de capturer l’activité complète du circuit pour le traitement entièr de la tâche, et d’éviter l’échantillonnage, qui est généralement effectué avec des plateformes basées sur des FPGA qui n’offrent pas une visibilité interne complète (Fig. 2).
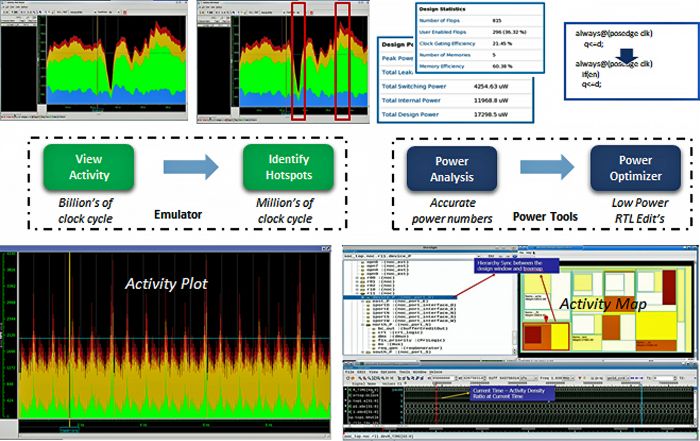
Figure 2 : Outils de puissance suivant l’analyse des tendances de consommation grâce à des cartes et des graphiques d’activité. (Source : Siemens EDA)
Il convient de mentionner qu’une grande entreprise de semi-conducteurs a changé d’avis sur le profilage précoce de puissance au niveau RTL après avoir assisté à l’exécution du banc d’essai d’Angry Birds sur un de ses SoC fonctionnant sur un émulateur. J’ai dû rire en pensant que ma fille jouait à Angry Birds sur son iPod, et que cette grande entreprise de semi-conducteurs exécutait le même programme sur un émulateur.
Quels sont les prochains développements que vous prévoyez ?
Un nouvel aspect de la conception, très complexe à gérer au stade du pré-silicium, concerne les chiplets, l’empilage de matrices et le conditionnement 3D pour les circuits intégrés.
Ma précédente discussion sur le profilage et l’analyse de puissance se basait sur une conception monolithique où tous les composants sont combinés sur une seule matrice. Nous nous intéressons maintenant aux conceptions mises en œuvre dans un boîtier 3D complexe. Dans nombre de ces conceptions, les cœurs de processeurs se trouvent sur une puce, les cœurs de GPU sur une autre, les mémoires sur une troisième, etc. et ils communiquent entre eux via un substrat ou un pont d’interconnexion multi-matrice (EMIB) embarqué (Fig. 3).
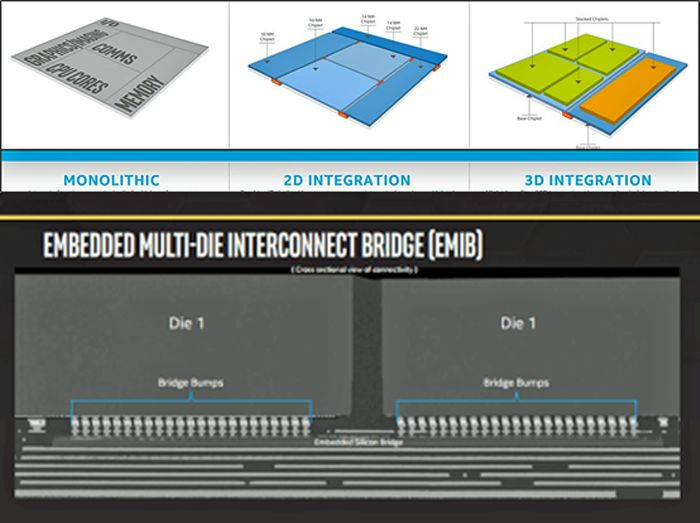
Figure 1 : Un pont d’interconnexion multi-matrice (EMIB) embarqué permet la communication entre les cœurs de processeur sur une matrice, les cœurs de GPU sur une autre et les mémoires sur une troisième. (Source : Intel)
Le profilage et l’analyse de puissance ainsi que l’analyse thermique sur la hiérarchie matérielle et la pile logicielle embarquée configurable répartie sur plusieurs matrices s’avèrent complexes et difficiles.
Nous devons créer la compilation modulaire et hiérarchique d’une conception complète en ciblant une plateforme d’émulation matérielle spécifique, et concevoir la capacité de parcourir, d’identifier et de déboguer l’activité basée sur le matériel/logiciel dans toute la hiérarchie de conception.

Lauro Rizzatti


